Since 2015, Google had released their free OCR (Optical Character Recognition) software and I had been liberally using it to parse text from pdfs (I started using it around 2017). It was much better than trying to copy and paste text from a pdf which always ended wonky. However, Google’s neural network based solution created in 2018 had passed under my radar. It’s about time we messed with it.
In summary, google’s open source OCR is a neural network based character recognition software. All you need is an image with some text and you can rip the text off of that photo. Unfortunately, it looks like the model they use is proprietary and cannot be found anywhere in Tesseract’s wiki.
Take for example this image:

You probably recognize it. It’s your standard Lorem Ipsum text you used to see on every microsoft word template. Let’s see how the ocr does in grabbing this text.
url <- "https://upload.wikimedia.org/wikipedia/commons/a/a7/Lorem_Ipsum_Arial.png"
library(tesseract)
# tesseract_download("lat")
lat <- tesseract(language = "lat")
text <- tesseract::ocr(url, engine = lat)
cat(text)
## Arial
##
## Lorem ipsum dolor sit amet, consetetur sadipscing
## elitr, sed diam nonumy eirmod tempor invidunt ut
## labore et dolore magna aliquyam erat, sed diam
## voluptua. At vero eos et accusam et justo duo
## dolores et ea rebum. Stet clita kasd gubergren, no
## sea takimata sanctus est Lorem ipsum dolor sit
## amet. Lorem ipsum dolor sit amet, consetetur
## sadipscing elitr, sed diam nonumy eirmod tempor
## invidunt ut labore et dolore magna aliquyam erat,
## sed diam voluptua. At vero eos et accusam et justo
## duo dolores et ea rebum. Stet clita kasd gubergren,
## no sea takimata sanctus est Lorem ipsum dolor sit
## amet. Lorem ipsum dolor sit amet, consetetur
## sadipscing elitr, sed diam nonumy eirmod tempor
## invidunt ut labore et dolore magna aliquyam erat,
## sed diam voluptua. At vero eos et accusam et justo
## duo dolores et ea rebum. Stet clita kasd gubergren,
## no sea takimata sanctus est Lorem ipsum dolor sit
## amet.
Notice that I used lat as the argument for the language. Little did you know lorem ipsum is not gibberish. I had to download the latin training text using tesseract_download() from their github repository. I think it did a pretty good job! It helps to have a standardized white background with arial text.
If we want to see how certain their estimates are, you can use the line below to get a table of estimates.
tesseract::ocr_data(url, engine = lat)
## word confidence bbox
##
## Arial 96.78439 12,16,90,45
## Lorem 96.92843 15,108,123,137
## ipsum 96.29134 138,108,240,145
## dolor 96.66776 254,108,345,137
## sit 96.97979 357,108,395,137
## amet, 96.19724 408,109,505,142
How about another language? Maybe a non-latin based character set. I grabbed a screenshot of a recipe for my favorite food: Mabo-Tofu. It’s so good. This image contains special characters and english letters as well. Let’s see how it does.

Unfortunately, there is some editing that needs to be done with the image before analysis. Let’s use some magick to fix the text. Simply, all I am doing is changing the character sets to be easier to recognize for the ocr. By performing a grayscale, I am limiting the color options. Then, I set a threshold to further define the black-white difference.
url <- "https://raw.githubusercontent.com/tykiww/imgbucket/master/img/tesseract/mapo_tofu.png"
library(magick) # Using magick to fix text.
mp <- image_read(url) %>% image_convert(type = "GrayScale") %>% image_threshold(c("black", "white"),threshold = .8)
Let’s pass this image through the engine.
# tesseract_download("jpn")
jap <- tesseract(language = "jpn")
mapo <- tesseract::ocr(mp, engine = jap)
cat(mapo)
## 豆腐 1丁
## 豚ひき肉 150g
## にんにく 1かけ
## しょうが 少タ
## 長ねぎ 172本
## 豆板普 小さじ1<2
## 人紹興酒(または酒) 大きじ2
## 人@租麺光 大きじ1
## @湊泊 大さじ1
## 人@穫がらスープのもと 大きじ172
## @砂糖 大きじ172
## 人水 250cc
## 水溶き片栗粉 適量
## ごま油 大さじ1/2
Here we notice some inconsistencies. There are definitely some mistakes with similar characters. Maybe if the font was closer to the training set and we set the letters to be larger and more defined. I’d give this an 8/10!
Let’s do something more challenging. How about identifying text from code?
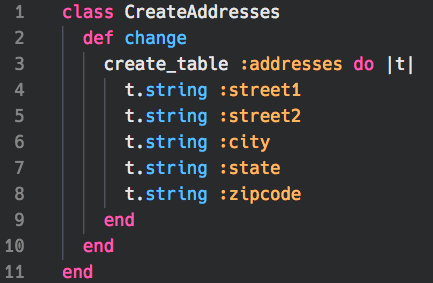
url <- "https://raw.githubusercontent.com/tykiww/imgbucket/master/img/tesseract/code_snippet.png"
t1 <- image_read(url) %>%
image_convert(type = "GrayScale") %>%
image_charcoal() %>% image_threshold(threshold = .80)
eng <- tesseract(language = "eng")
code <- tesseract::ocr(t1,engine = eng)
## library(stringi)
## um <- stri_split_lines(code, omit_empty = FALSE)[[1]]
## stri_trim_left(substring(um[um!=""],3))
cat(code)
## a class CreateAddresses
##
## 2 def change
##
## 3 create_table :addresses do |t|
## 4 t.string :street?
## 5 t.string :street2
## 6 t.string :city
##
## 7 t.string :state
## 8 t.string :zipcode
## 9 end
##
## 10 end
##
## ai end
Not bad! This may need some modifications, but overall it does a really good job! It looks like most of the challenges appear from overfitting. If the text isn’t uniform in color, we see some errors.
Overall, we were able to make some simple modifications to our images to fit it well into the Tesseract model provided to us by Google. This goes to show that not everything needs to be done by scratch. Sometimes, there is no need to train your own model (just use a pre-trained VGG). It really depends on if it fits the bill. I can’t really think of too many business applications to this but I’m sure you can go on to create some neat resume scrapers.