Webscraping with Rvest and investigating mod 10.
So, I have this McDonalds app. Really convenient, especially for any hungry college student looking for ways to save money. Yet, there’s a problem with my card. It just doesn’t register with the app. How disappointing! Usually they have those 1 dollar deals to get any sandwich. That’s my favorite one (This is in no way a paid add, I’m just always ready for some cheap food 笑).

Upon being frustrated at how my card didn’t work, I tried to troubleshoot this problem on the internet. Unfortunately, I couldn’t find any solutions, but I ended up finding something even more interesting. This was the mod 10 (modulus 10) or Luhn algorithm. This is an algorithm that is heavily used to generate credit card numbers and ID numbers. I guess it isn’t safe to generate passwords because if someone found out every value except the last number of my card, I’d be screwed.
The Luhn Algorithm
The rules are…
- Generate a random number. (ie. 37326). Now let’s find the ‘check’ value.
- The ‘check’ digit is the last digit: the unique identifier for whether or not these credit cards are valid.
- Flip the random number generator around (use function
rev()), then double every second value.- 62373 -> 12, 2, 6, 7, 6
- If any of the digits exceed 9, add the digits together (12 would turn into 1 + 2 = 3).
- 6, 2, 6, 7, 6
- Next, sum the values
- 6 + 2 + 6 + 7 + 6 = 27
- Now multiply that value by 9
- 27 * 9 = 243. The last value 3 is your ‘check’ digit.
- Finally, you will have a string that has the original random numbers including the ‘check’ digit.
- 373263
The pseudo-code for this algorithm is right here. It’s rather simple. You probably won’t need it if you have the rules.
With this algorithm, I decided to make a credit card generator for some of the main credit networks (ie. Visa, Amex, MasterCard, etc.). rvest() scraping was also incorporated for some variety.
Data Scraping
Let’s get started by downloading the only necessary library. The rest will be performed in Base R.
library(rvest)
The only place I could find useful information about typical credit network values was on wikipedia. The table I want to retrieve looks like this.
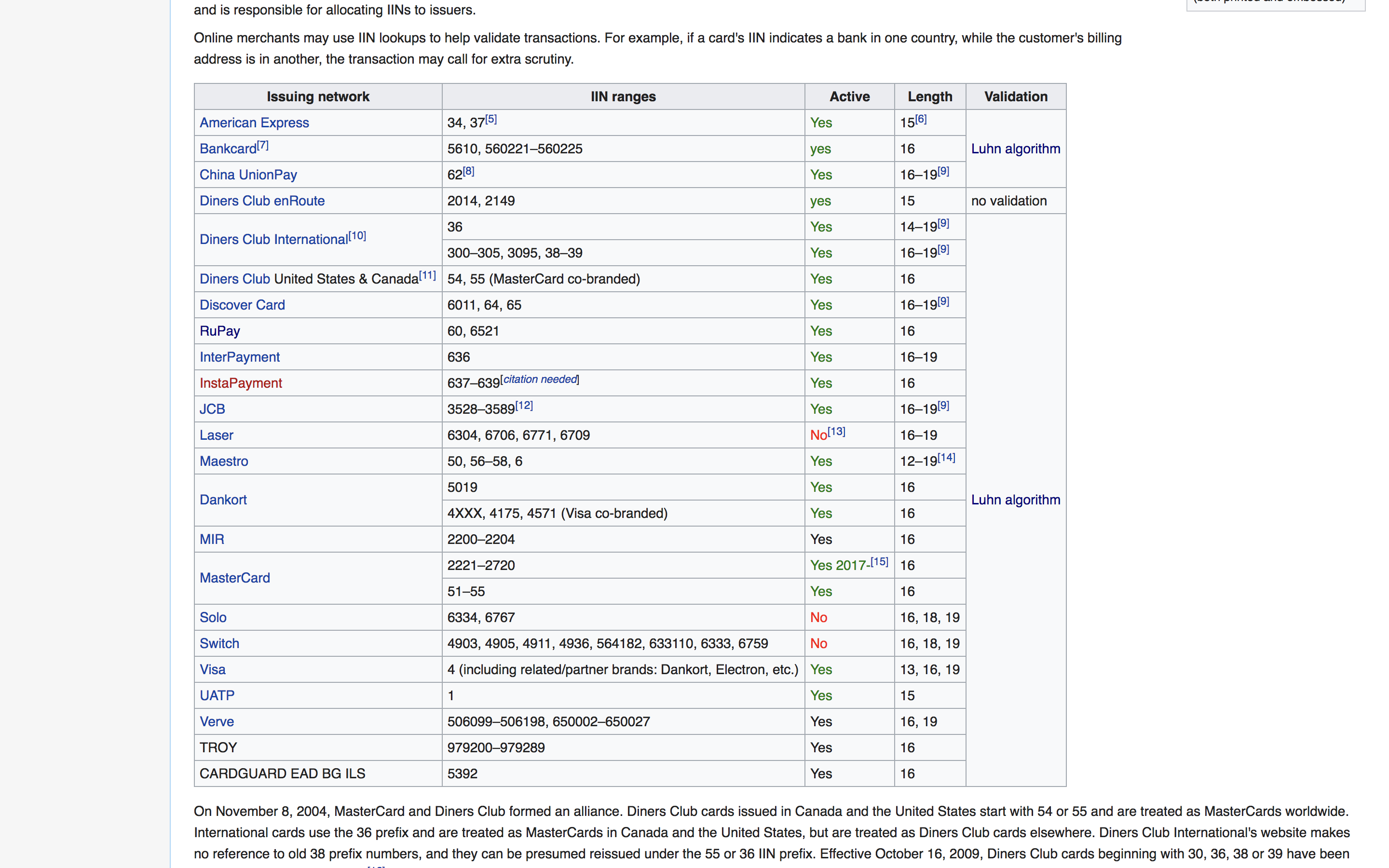
Before we read anything in, let’s grab the xpath from our inspect element of the table. Right click on your chrome or firefox window on the page and select “inspect”. This will pull up a sidebar that shows us the html, css, and other properties in the window.

From there, start clicking on the html elements that highlight the specific portions of the page. If you do it well, it will narrow down so you only have the table showing up.

Once you get to the portion that highlights the desired table (usually in between the section that specifies “<table…), just right click and copy the xtable value! This will make sure exact table you are searching for.

Interesting huh? I guess we can apply this in many other situations where we are scanning and grabbing lots of information from many pages. It’s also possible to search multiple volumes of values on google from rvest and compile data from multiple sources not on one page. This will be shown on a future post using rselenium.
Now that we have that out of the way, let’s use the information we need to scrape the table.
This can all be done in one simple step. read_html() comes from the xml2 package, and the html_nodes() and html_table() both come from the rvest package. The %>% operator fun to toy with. I am actually not completely used to using it yet, but I realized that it simplifies my code for this example instead of having to vectorize everything. I’ll hopefully be using them more often.
All it is, is just taking a url into the read.html(), searching for the xpath from our inspected element.
# specify url and xpath
path <- "https://en.wikipedia.org/wiki/Payment_card_number#Major_Industry_Identifier_.28MII.29"
xp <- '//*[@id="mw-content-text"]/div/table[1]'
credit <-
path %>%
read_html() %>%
html_nodes(xpath = xp) %>%
html_table()
credit <- credit[[1]] # first list element.
head(credit)
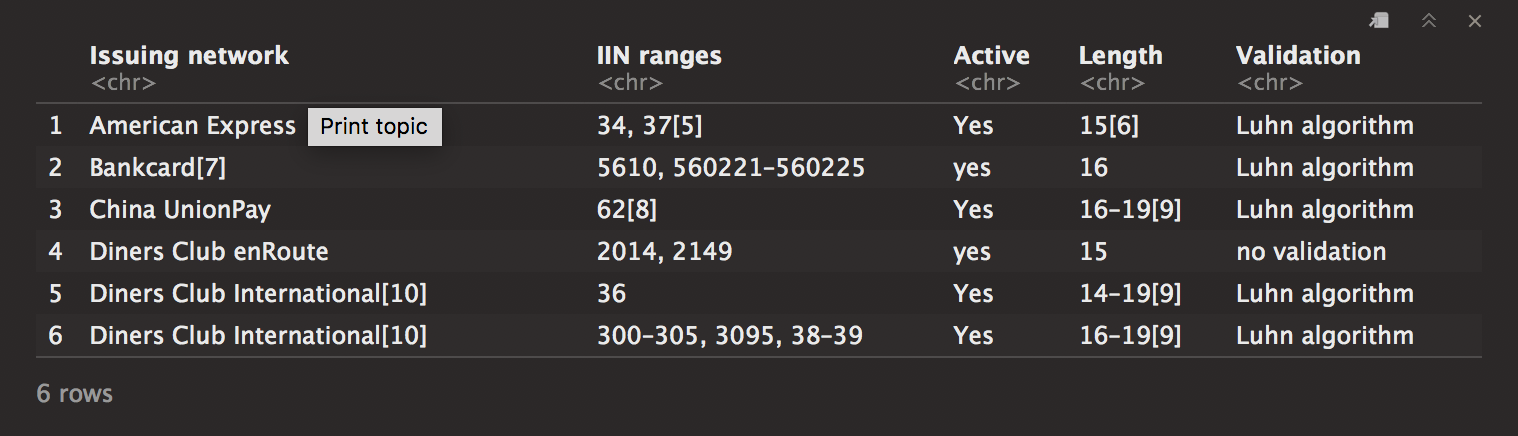
Now I’ll just clean up the information really quick. This one shouldn’t be too difficult.
# create function to get rid of citation boxes.
annoying <- function(x) {
gsub ("\\[[0-9]+\\]","",x)
}
credit <- sapply(credit, function(x) annoying(x) )
# only columns of interest. Come on, dummy. Use the `dplyr::select()` function...
networks <- credit[c(22,18,19,1,8,3,12,14),c(1:2,4)]
From here, I’m only going to pull out the Credit card networks that I want. I am only going to select the most heavily used international cards. I just pulled up a google search with the most used networks. Sorry to bankcard, rupay, and all others…
## Visa [22], Mastercard [18,19], Amex [1], Discover [8], UnionPay [3], JCB [12], Maestro [14].
We’ll put this portion aside for a bit and revisit it later.
Algorithm
Let’s just work on coding up the algorithm for now. Later, I’ll show you how I used the information to create a credit card number generator given a specific network.
Step 1 is to generate random digits for how long we want our credit card to be. I’ll call this base1. For a credit card value of 15 = x, we will generate a random sample of x-1 and reverse those values.
x <- 15
base1 <- sample(0:9,x-1, replace = T)
# reverse the numbers
split <- rev(base1)
Now we’ll take the odd values and double them! I passed the values through a for loop and used my own function to take apart the digits.
# identify odd and even values.
# Multiply odd values
even <- split[-seq(1,length(split),2)]
odd <- split[seq(1,length(split),2)] * 2
# function that takes digits and sums them.
digsum <- function(x) sum(floor(x / 10^(0:(nchar(x) - 1))) %% 10)
# mitigate double digits add them.
anchor <- numeric(0)
for (i in 1: length(odd)) {
if (odd[i] > 9) {
anchor[i] <- digsum(odd[i])
} else anchor[i] <- odd[i]
}
Now we’ll sum up the even and odd vector elements and multiply them by 9 to extract the check value. It is rather difficult to have to take numerical values and take specific values when they are random, so regex may be applied to determine the last value.
splitvec <- function(x) strsplit(gsub("(.)\\B","\\1 ",x), " ")[[1]]
check <- sum(anchor,even) * 9 # combine and multiply by 9
check <- splitvec(check)
check <- as.numeric(tail(check,1)) # identify check value
check
## [1] 8
Our check value seems to be 8! We can stick that value back on the original random sample we created.
paste(c(base1,check), collapse = "")
## [1] "391215822812658"
Put this number through an algorithm checker site and you’ll see that it works! Now you have a 15 digit credit card number that passes the luhn test. Kinda neat huh?
Application
Now I’ll show you how I used the scraped information:
Here, I decided to make two inputs. One x if you were just trying to pass the regular luhn algorithm of a certain length, and another input: network. This specifies which major credit number to generate given the specific network. You can see how the if else statements determine the base numbers and the rest of the code remains intact!
The IIN number from the table allows for the differentiation of each card network. It stands for the issuer identification number. This value is a sort of domain for their own company. If you take a look at your card, you’ll notice that visa always starts with a 4, Amex always starts with a 34 or 37, and so on. Depending on those values, we can randomize and identify which values come up. Give it a try by yourself! It works really well.
mod10 <- function(x, network = "luhn") {
# run functions
digsum <- function(x) sum(floor(x / 10^(0:(nchar(x) - 1))) %% 10)
splitvec <- function(x) strsplit(gsub("(.)\\B","\\1 ",x), " ")[[1]]
visa <- 4
amex <- c(34,37)
union <- 62
jcb <- 3528:3589
maes <- c(50,56:58,6)
# conditional for each credit card network
if (network == "Visa") {
size <- sample(c(11,14,17),1, replace = T)
base1 <- c(visa,sample(0:9,size, replace = T))
} else if (network == "MasterCard") {
part1 <- sample(51:55,1, replace = T)
part2 <- sample(2221:2720,1, replace = T)
size1 <- 16-2-1
size2 <- 16-4-1
ifelse(sample(0:1,1) == 1,
basec <- c(splitvec(part1),sample(0:9,size1, replace = T)),
basec <- c(splitvec(part2),sample(0:9,size2, replace = T)))
base1 <- as.numeric(basec)
} else if (network == "American Express") {
part1 <- sample(amex,1, replace = T)
size <- 15-2-1
basec <- c(splitvec(part1),sample(0:9,size, replace = T))
base1 <- as.numeric(basec)
} else if (network == "Discover") {
part1 <- sample(c(64,65),1, replace = T)
part2 <- 6011
size1 <- sample(13:16,1,replace=T)
size2 <- sample(11:14,1,replace=T)
ifelse(sample(0:1,1) == 1,
basec <- c(splitvec(part1),sample(0:9,size1, replace = T)),
basec <- c(splitvec(part2),sample(0:9,size2, replace = T)))
base1 <- as.numeric(basec)
} else if (network == "UnionPay") {
size <- sample(c(13:16),1, replace = T)
basec <- c(splitvec(union),sample(0:9,size, replace = T))
base1 <- as.numeric(basec)
} else if (network == "JCB") {
part <- sample(jcb,1, replace = T)
size <- sample(c(11:14),1, replace = T)
basec <- c(splitvec(part), sample(0:9,size, replace = T))
base1 <- as.numeric(basec)
} else if (network == "Maestro") {
part1 <- 6
part2 <- c(50,56,67,58)
size1 <- sample(10:17,1, replace = T)
size2 <- sample(9:16,1, replace = T)
ifelse(sample(0:1,1) == 1,
basec <- c(part1,sample(0:9,size1, replace = T)),
basec <- c(splitvec(part2),sample(0:9,size2, replace = T)))
base1 <- as.numeric(basec)
} else if (network == "Luhn") base1 <- sample(0:9,x-1, replace = T)
# reverse the numbers
split <- rev(base1)
# identify odd and even values.
# Multiply odd values
even <- split[-seq(1,length(split),2)]
odd <- split[seq(1,length(split),2)] * 2
# mitigate double digits -9 | add the digits.
anchor <- numeric(0)
for (i in 1: length(odd)) {
if (odd[i] > 9) {
anchor[i] <- digsum(odd[i])
} else anchor[i] <- odd[i]
}
check <- sum(anchor,even) * 9 # combine and multiply by 9
check <- splitvec(check)
check <- as.numeric(tail(check,1)) # identify check value
paste(c(base1,check), collapse = "")
}
mod10(x = 14)
mod10(network = "Visa")
## [1] "391215822812658" # mod10(x = 14)
## [1] "4727059036057" # mod10(network = "Visa")
The first item is a luhn algorithm of length 14, could be any credit card number. The second element is the specified visa credit card number. Pass the second string through here to confirm.
There is definitely more information that missing besides these rules to generate a fake credit card number, but that should be enough. It seems like an effective technique to process unique identification numbers for your company or even ‘fake’ credit card numbers. Odds are, someone has those values, so maybe you should be careful.
Note here, that I never used this to pay for anything. However, I’m still a bit angry that my McDonald’s app is being dumb. I really want those one dollar deals…